· Samir Abid · AI Development · 9 min read
What I Learned Building a RAG System Over the Last Year
Lessons from building a RAG system over a year: vector search, hybrid search, re-rankers, graph databases, and how AI changes the cost of software experimentation.

For the last year, I have been building an AI knowledge assistant. The basic idea is simple: take a company’s documents and make them easier to ask questions of.
When I started, I thought the hard part would be making the AI accurate. Getting it to understand context properly. Making sure it did not just make things up.
Those things were hard.
But what I actually learned was slightly different. It was about how fast you can try things now, and what that changes about building software.
This is what happened.
Starting Point
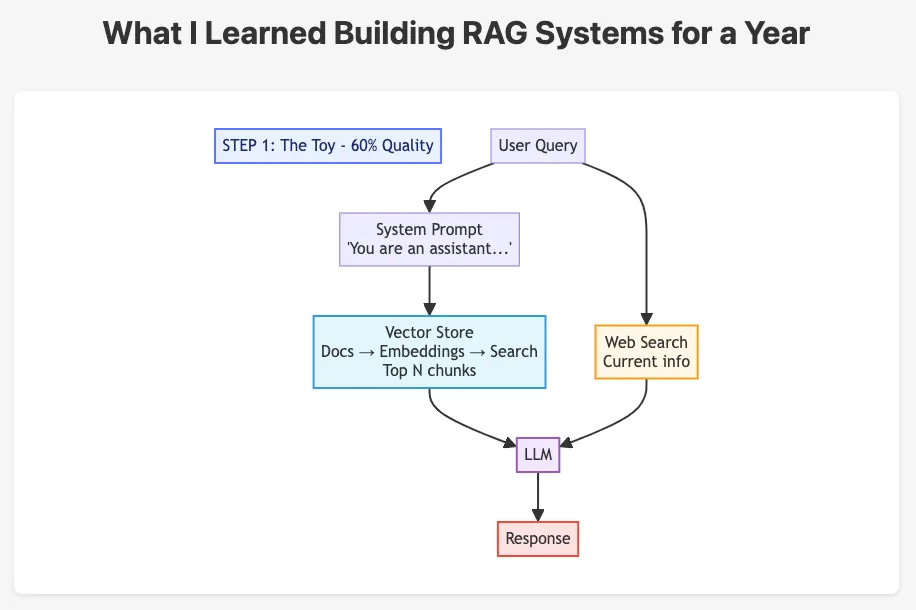
I did what everyone does first. Set up a vector database. That’s the standard approach for this kind of system.
The way it works is straightforward enough. You take your PDFs, break them into chunks, turn them into mathematical representations, and store them in a database. Someone asks a question, the system finds relevant chunks, sends them to the AI, and you get an answer back.
Sometimes this worked really well. Ask about a project and you’d get a solid summary.
Sometimes it did not work at all. Ask for a specific part number and you might get the right answer. Or you might not.
The part number problem bothered me. If I had used regular keyword search, literally searching for “1234”, I would have found it instantly.
But I had switched to semantic search, which tries to understand meaning rather than just matching words. It could find documents about specifications, but not always that specific specification.
I spent quite a bit of time trying to tune this. Changing how the system was set up. Different ways of breaking up the documents. Trying to get it more consistent.
I got it working, sort of. But it was hit and miss.
What I found was a pattern: you make a choice about how the system works, and some things get better while other things get worse.
But even then, the interesting part was the pace. I was trying different approaches in days. Not weeks. Not months. Try something, see what improved, see what got worse, then move on to the next thing.
The Hybrid Approach
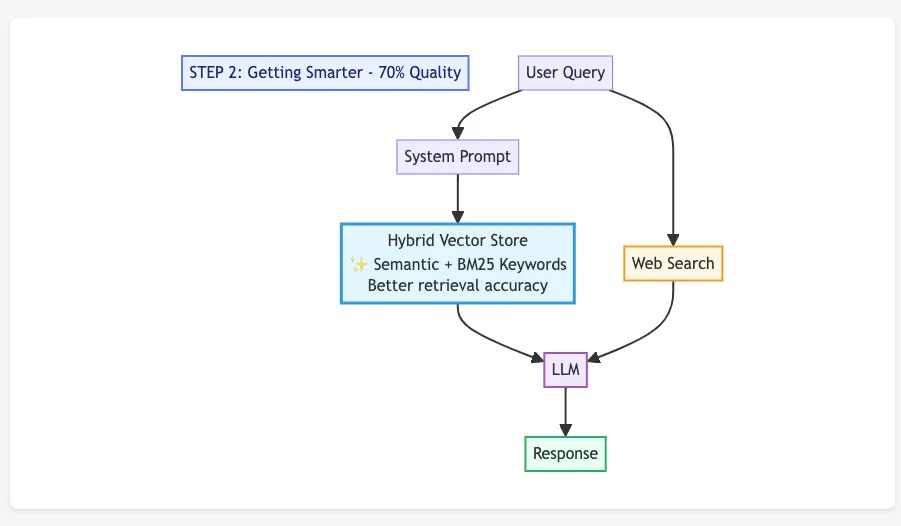
Then I found a better middle ground. Run semantic search and regular keyword search at the same time, then blend the results together.
So now “specification 1234” would get caught by the keyword part. Questions like “how are these projects performing” would get handled by the semantic part.
That helped. Things got noticeably more consistent.
The useful lesson was not only that hybrid search worked. It was that I could implement and test it in a few days. In the past, trying a different search architecture would have carried more process around it. This time, I could test it and let the result decide.
The Knowledge Problem

As I added more documents, a new problem showed up.
Ask a question that was mentioned in 50+ documents and the system would try to send too much information to the AI. The answer became vague because the context was too noisy.
I added a re-ranker. That is another model that looks at all the chunks you found and picks out the most relevant ones before sending them along.
So instead of: find 30 chunks → send to AI, it became: find 30 chunks → re-rank them → keep the best 5 → then send to AI.
This made a big difference in quality.
But it also made everything slower and more expensive. More AI calls, more processing. You find yourself weighing the same trade-offs again and again: speed, quality and cost.
The thing is, I could test this in under a week. Add the re-ranker, see if it actually helped, measure the difference.
In a more traditional process, adding a whole new layer like this would have been a major decision. Architecture reviews. Team discussions about whether it was worth it. Here, I tested it. It worked. I kept it.
That’s when I started noticing the pattern.
The Graph Database
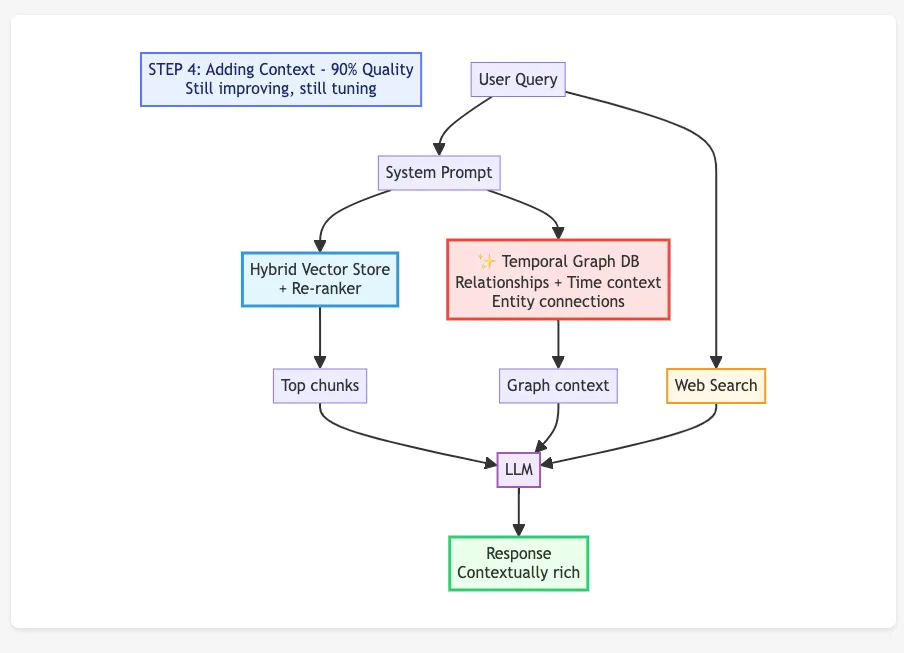
Eventually I hit a different kind of problem. Context wasn’t just living inside documents. It was living between them.
Which projects linked to which clients. Who worked with whom. How things evolved over time.
I had been looking at graph databases. A useful way to think about them is as relationship maps. They track how things connect. I looked into Neo4j, which can handle time-based relationships.
The idea was to give all those vector chunks a structure to hang onto. Not just floating content, but content connected to other content in meaningful ways.
This helped too, but for a different reason. It made the system better at using relationships, not just matching content.
But here is the bit that made me stop and think. When I looked into implementing this, I got a roadmap from the AI. It said this would take about six weeks.
We did it in three hours.
Not because I am particularly clever. Because the AI could help me write the code, spot the mistakes and suggest better approaches. I stayed focused on the design, what I wanted it to do, and the implementation went much faster than expected.
That is when the bigger point became hard to ignore. This is not just about building a better RAG system. It is about what happens when you can try things that used to take weeks in a matter of hours.
What This Actually Changes
Think about how technical decisions normally work.
Someone suggests using a new technology or approach. Management gets nervous. “How long will this take? How much will it cost? How sure are we it’ll actually work?”
Developers push back when you want to change direction. “We just spent three weeks implementing this and now you want to change it?”
So you end up being conservative. Sticking with what you know. The organisational friction alone makes experimentation expensive.
But what if that six-week implementation is actually three hours?
What if trying a completely different approach takes a couple of days instead of a couple of months?
The risk calculation changes.
You can try things you would have dismissed as too uncertain. The friction is much lower because it is three hours, not three sprints. You can test five different approaches instead of debating which single approach to commit to.
I probably tried more architectural variations in this one year than I would have tried in five years of traditional development. Not because I was smarter about it. Because I could actually try them.
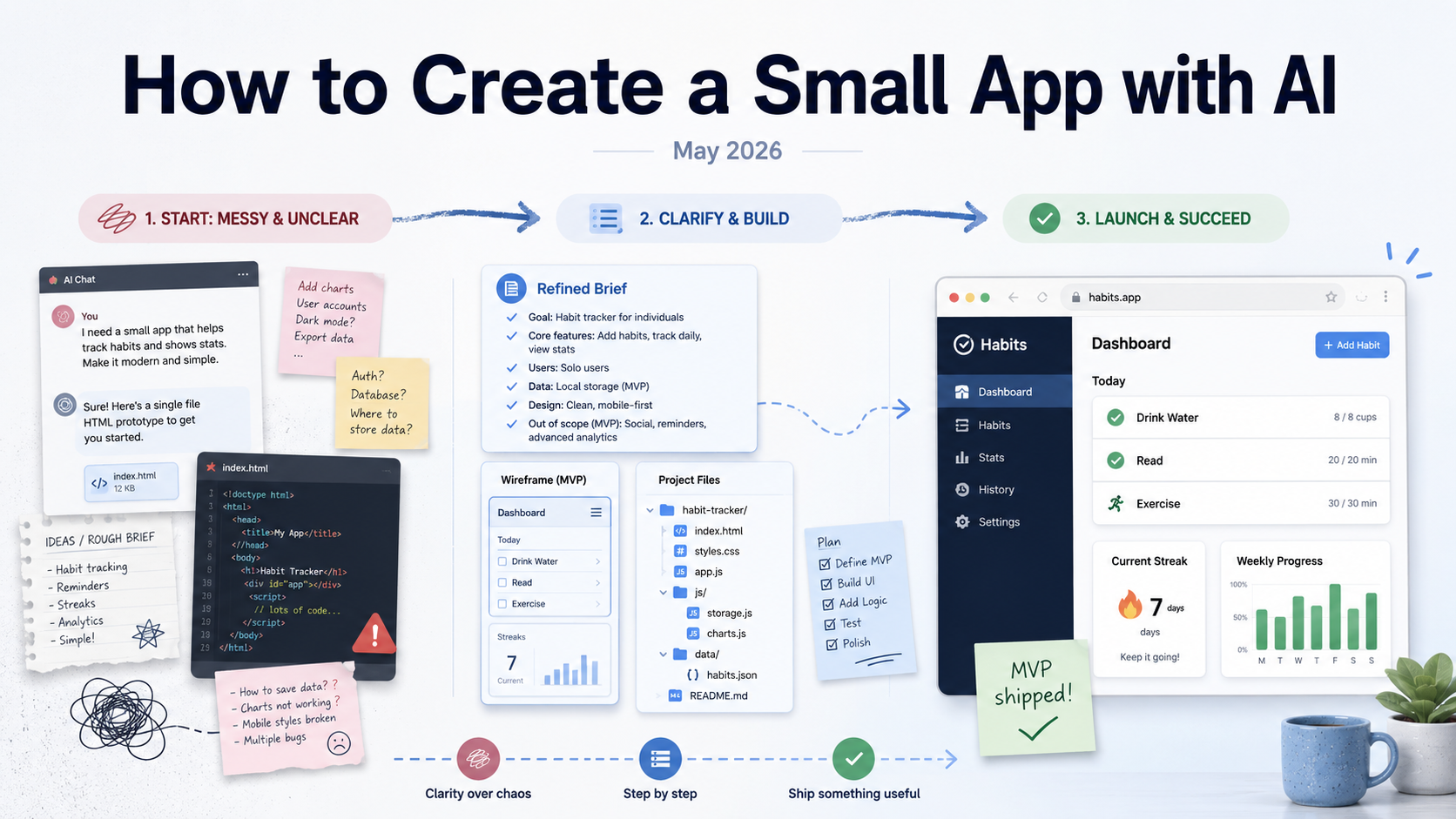
This same pattern is starting to show up in smaller software projects too. If you want a practical example of that, I wrote a May 2026 guide here: How to Create a Simple App with AI in May 2026.
What This Means for RAG Projects
A useful RAG system is not just “documents in, answers out”.
The parts that matter are:
- Retrieval: can it find the right material?
- Ranking: can it choose the best material from the results?
- Context: does it understand relationships between documents?
- Evaluation: can you tell whether the answer improved?
- Cost and latency: is the better answer worth the slower response?
That is where most of the work lives.
The practical lesson is that each layer solves one problem and usually introduces another. Vector search helps with meaning, but can miss exact terms. Keyword search helps with exactness, but misses intent. Re-rankers improve quality, but add cost and latency. Graph databases add context, but need structure.
The job is not to find the perfect architecture at the start. The job is to make the system easy enough to test that you can learn which trade-offs matter for your use case.
What Hasn’t Changed
I should be clear. It is not all easy.
Things still break. I still spend days debugging. The AI doesn’t get it right every time.
And you’re still dealing with the same fundamental trade-offs:
- Cost: Every layer you add costs more to run
- Speed: Every layer makes the system slower
- Quality: That last 10% is still hard to get right
But I can test different solutions to those problems in days instead of months.
Here is a small example. I eventually asked the AI to write its own system prompts. I gave it examples of good answers and poor answers, then let it iterate on improving the prompts.
It actually worked. Measurably better results.
In the past, this would’ve been a two-week optimization project. Instead it was an afternoon experiment.
That keeps happening. Things that would have been projects become experiments.
What This Means
I set out to build a RAG system. And I did. It has gone from a fun prototype to something genuinely useful.
But what I actually learned was about the development process itself.
When I look back at this year, what I have been able to build and test would previously have needed a much larger team and a much longer timeline.
Because in a team, when you suggest replacing three weeks of work to try something different, people push back. Not because they are wrong to push back. The time has already been spent. People are tired. Momentum matters.
Here, that friction was much lower.
I could stay closer to design mode, thinking about what I wanted the system to do, rather than spending all my time in the weeds of implementation.
The AI was involved at every layer. Advising, coding, architecting. But it did not have to be an AI project specifically. This same pattern applies to many kinds of software work.
The Question That Matters
If you are thinking about AI for your business, the question is not only “what can AI do?”
The better question is: “Are we set up to learn faster than we did last year?”
Because the advantage is not only what AI builds. It is what AI enables you to try.
The old calculation, “that is too risky, too uncertain, takes too long”, is changing.
If one team can test five approaches while another is still debating the first, the difference will show up in what gets learned.
I do not have this all figured out. I am still learning. Still finding limitations and surprises.
But the change is not only about AI systems. It is about what happens when the cost of trying something new drops materially.
That changes how technical decisions can be made.
If you want the broader business map of where this kind of work fits, see What AI Can Actually Do for Your Business Today.
If you are working through similar questions, I would be interested to hear what you are seeing. Get in touch.